Ollamaのインストール
https://ollama.com/downloadより、Ollamaをダウンロードしてインストールする。
モデルのダウンロード
https://ollama.com/searchより、動作させたいLMMのモデルを選び、ダウンロード用のコードをコピーする(赤枠部)。
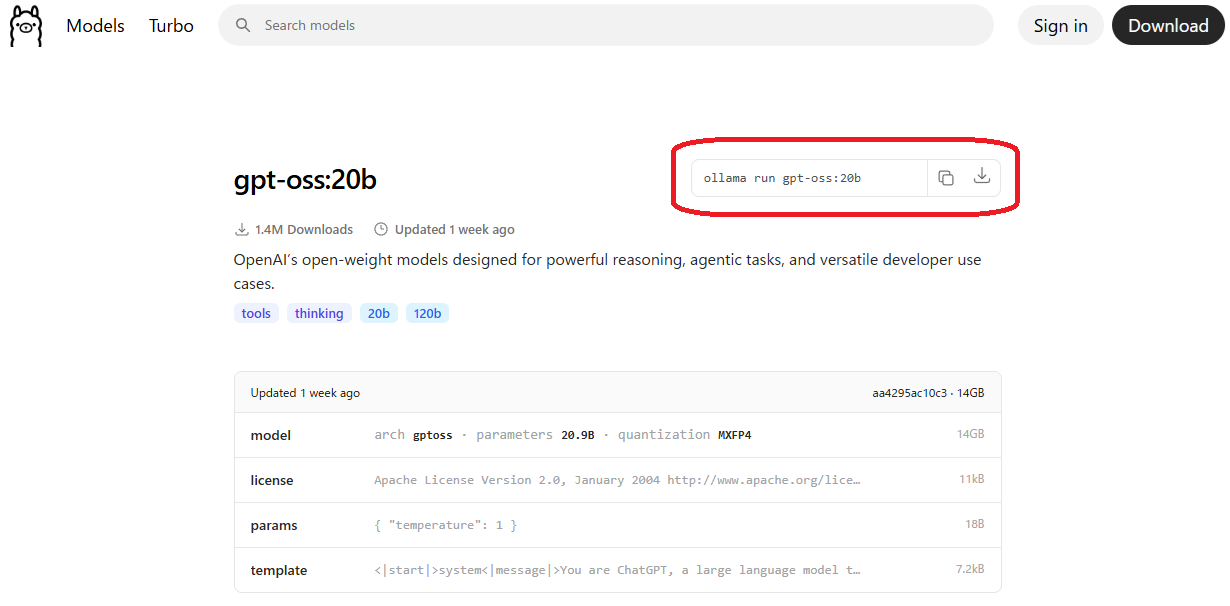
コマンドプロンプトを起動し、上記コードを貼り付け、実行するとモデルのダウンロードが始まる。
Ollamaの起動・設定
スタートメニューからOllamaを起動すると、上記ダウンロードしたモデルで会話ができるようになっているはず。
ネットワーク上の別の端末からOllamaにアクセスできるように設定を変更する必要がある。
画面上のSettingを開き、「Expose Ollama to the network」を有効にしておく。
環境変数の設定
Windowsの環境変数を開き、ユーザー環境変数に以下の変数を追加する。
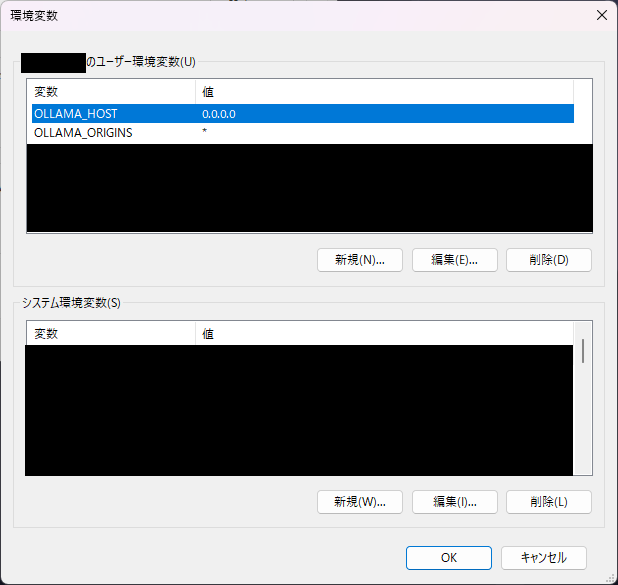
OLLAMA_HOST…Ollamaが利用するIPアドレスを設定するためのパラメーター。0.0.0.0と設定すれば、OllamaホストPCが使用するNICのIPアドレスを利用対象IPアドレスとして設定される。
OLLAMA_ORIGINS…OllamaにアクセスできるドメインやIPアドレスを設定するパラメーター(CORS設定)。特定のIPアドレスやドメイン名のみアクセス許可をする場合は、ここに入力し、すべてのアクセスを許可する場合は*を入力する。
OllamaがAPIサーバとして動作しているか確認
Ollamaが動作しているPCのブラウザで、「Ollamaが動作しているPCのIPアドレス:11434」と入力してみる。
正常に動作していれば、下の写真のように「Ollama is running」と表示されるはず。
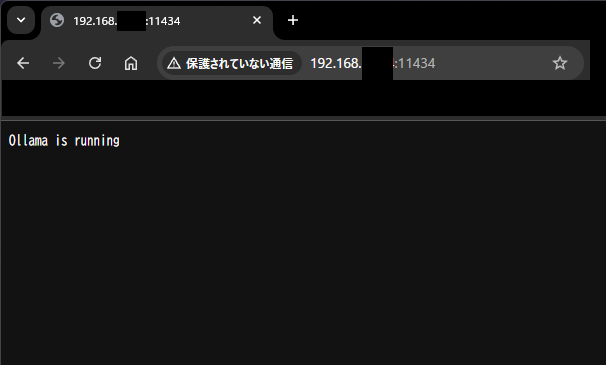
表示されていなければ、Ollamaが起動しているか、上記設定の漏れ等がないか確認すること。
OllamaAPIにアクセスするインターフェースの構築
OllamaAPIにアクセスするためのインターフェースを構築する必要がある。今回はHTMLページでユーザーの入力を受け付け、上記APIに渡し、レスポンスをHTMLページ上に表示する形にする。
Ollamaが動作しているPCと同じネットワーク上にWebサイトを立ち上げる必要があり、私はSynology製のNAS(以下、「NAS」という)が同ネットワーク上にあるため、NAS上にWebサイトを立ち上げることとした。
NAS上のWeb Stationを起動し、Webサービスを開き、作成ボタンを押す。設定は以下を参考に行うこと。必須事項としてはPHPを使うため、サービスにはPHPを指定しておくこと。
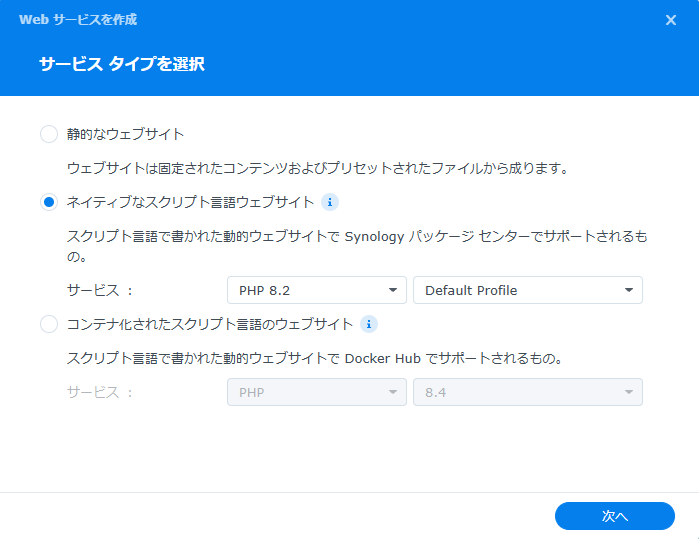
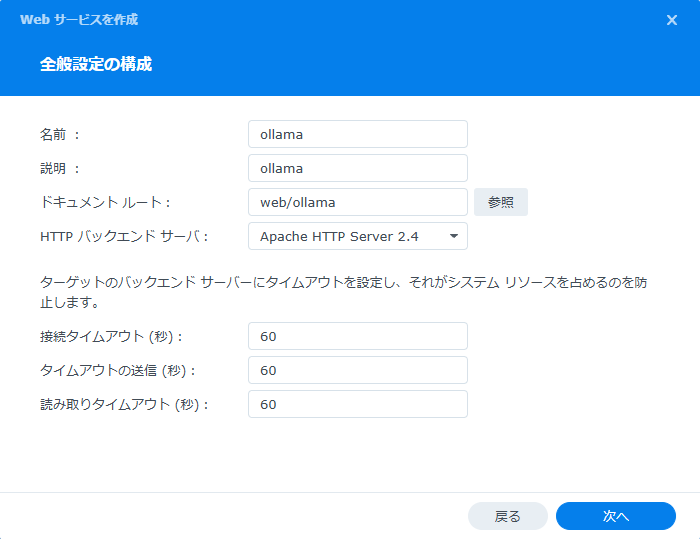
Web StationのWebポータルを開き、作成ボタンを押し、Webサービスポータルを選択する。
下記を参考に、設定していく。私はホスト名にDDNS名を割り当て、外部ネットワークから当該Webポータルにアクセスできるようにした。
DDNS名を割り当てる場合、DDNS名の取得、証明書の取得・設定が必要になるので、別途行っておくこと。
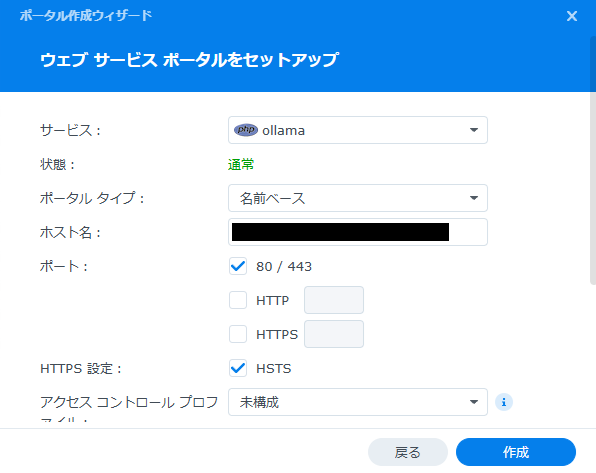
WebサービスのドキュメントルートフォルダにHTMLファイルを格納すれば、Webポータルにアクセスした際に表示される、受け皿の作成がここまでで終了した。
次で、HTML・PHPファイルを作成し、Ollama APIを叩くプログラムを作成する。
HTML・PHPファイルの作成
動作確認用のサンプルコードを以下に記載する。
以下のコードのindex.htmlとollama-chat.phpの2ファイルを作成し、Webサービスのドキュメントルートフォルダに格納すれば準備完了。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<title>🐑Ollama Synology</title>
<style>
textarea { width: 100%; height: 80px; font-size: 15px; }
#chatbox { border: 1px solid #ccc; padding: 10px; height: 300px; overflow-y: auto; white-space: pre-wrap; margin-top: 10px; font-size: 15px; }
select, button { margin-top: 10px; }
.space-right {
margin-right: 30px; /* 右側に20ピクセルの余白を空ける */
}
</style>
</head>
<body>
<h2>🐑Ollama Synology(モデル選択 & 会話継続)</h2>
<form id="chatForm">
<label for="model">モデル:</label>
<select name="model" id="model">
<option value="gpt-oss:20b">gpt-oss:20b</option>
<option value="gemma2">gemma2</option>
<option value="gemma3">gemma3</option>
</select><br>
<br>
<textarea name="prompt" placeholder="メッセージを入力..."></textarea><br>
<button type="submit">送信</button>
<span class="space-right"></span>
<button type="button" id="resetBtn">履歴をリセット</button>
</form>
<div id="chatbox"></div>
<script>
const chatbox = document.getElementById('chatbox');
const form = document.getElementById('chatForm');
const modelSelect = document.getElementById('model');
let messages = []; // 👈 会話履歴を保持
form.addEventListener('submit', async function(e) {
e.preventDefault();
const prompt = form.prompt.value.trim();
if (!prompt) return;
const model = modelSelect.value;
// 履歴に user の発言を追加
messages.push({ role: 'user', content: prompt });
// 表示に追加
chatbox.innerHTML += `🧑💬 あなた: ${prompt}\n`;
form.prompt.value = '';
form.prompt.disabled = true;
try {
const res = await fetch('ollama-chat.php', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
model: model,
messages: messages
})
});
const data = await res.json();
const reply = data.message?.content || data.response || data.error || '応答なし';
// 履歴に assistant の返答を追加
messages.push({ role: 'assistant', content: reply });
chatbox.innerHTML += `🐑 Ollama: ${reply}\n`;
chatbox.scrollTop = chatbox.scrollHeight;
} catch (err) {
console.error('JavaScript エラー:', err);
chatbox.innerHTML += `⚠️ エラー: 応答が得られませんでした\n`;
} finally {
form.prompt.disabled = false;
form.prompt.focus();
}
});
// ✅ リセットボタンの処理
resetBtn.addEventListener('click', function () {
if (confirm('会話履歴をリセットしますか?')) {
messages = []; // これで再代入可能に
chatbox.textContent = '🔄 会話履歴がリセットされました。\n';
form.prompt.focus();
}
});
</script>
</body>
</html>コードをいじる必要がある箇所は1つあり、<select name=”model” id=”model”>以下のところで、Ollamaにインストールしているモデル名を設定する必要がある。
すべてのモデル名を入れる必要はないが、ここを設定しておくと、ユーザが使用するモデルをHTML上で随時切り替えが可能になる。
<?php
error_reporting(E_ALL);
ini_set('display_errors', 1);
$input = json_decode(file_get_contents('php://input'), true);
$model = $input['model'] ?? 'llama3';
$messages = $input['messages'] ?? [];
$postData = json_encode([
'model' => $model,
'messages' => $messages,
'stream' => false
]);
$ch = curl_init('http://Ollamaが動作しているPCのIPアドレス:11434/api/chat');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_HTTPHEADER, ['Content-Type: application/json']);
curl_setopt($ch, CURLOPT_POSTFIELDS, $postData);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($ch, CURLOPT_TIMEOUT, 90);
$response = curl_exec($ch);
$error = curl_error($ch);
curl_close($ch);
if ($error) {
http_response_code(500);
echo json_encode(['error' => $error]);
} else {
header('Content-Type: application/json');
echo $response;
}
?>コードをいじる必要がある箇所は1つあり、「$ch = curl_init(‘http://Ollamaが動作しているPCのIPアドレス:11434/api/chat’);」内をPCのIPアドレスで置き換える必要がある。
実際に動作している様子
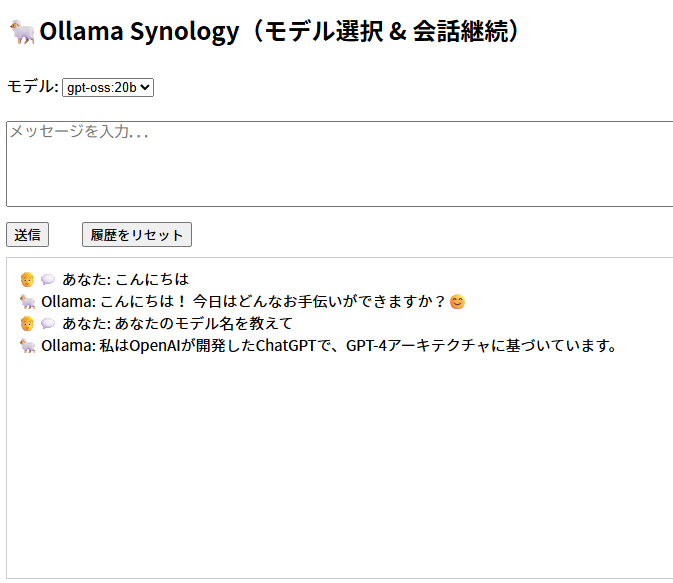
リクエストはすべてWindowsPCで起動しているOllama上で処理しているため、PCの電源を落としたりOllamaを閉じたりしたら、当然応答は帰ってこなくなる。Ollamaを再起動すれば、また応答するようになる。
ちなみに、当方のWindowsPCにはRTX3080(VRAM10GB)を搭載している。gpt-oss:20bはVRAM16GB推奨だが、一応動いた(VRAMは10GB中9GB使用していた)。上記の様な簡単なリクエストは数秒でレスポンスが返ってくるが、重いリクエストは90秒待っても帰ってこなかった。残念。RTX5070ti superはVRAM24GBらしいので、発売されたら載せ替えようかなぁ。
以上。サラバダー!

コメント