1.Ollamaをホストしている端末自身でContinueを利用する場合
①Ollamaをインストールする
以下のリンク先からインストーラーをダウンロード・インスコしておく。ついでに使用したいモデルもOllamaにセットアップしておく。
基本的にContinueを使用している間(チャット・入力支援など)はモデルがロードされっぱなしになるので軽めのモデルがおすすめ。
私はQwen2.5-Coderを使ってます。VRAMの使用量は1.4GB程度です。

https://ollama.com/library/qwen2.5-coder
②VSCodeにContinueをインストールする
以下の拡張機能をインストールしておく。

③-1 VSCodeの設定(Ollamaをホストしている端末自身でContinueを使う場合)
公式ドキュメントは以下のリンク先にあります。ザックリ使えるよう備忘録程度の内容です。


Continueをインストールすると、プライマリサイドバーにオレンジ枠のアイコンが追加されます。
クリックするとだいたいこんな感じで表示されると思います(既にセットアップ済みの状態なのでインスコした直後とは違うカモ🦆)。
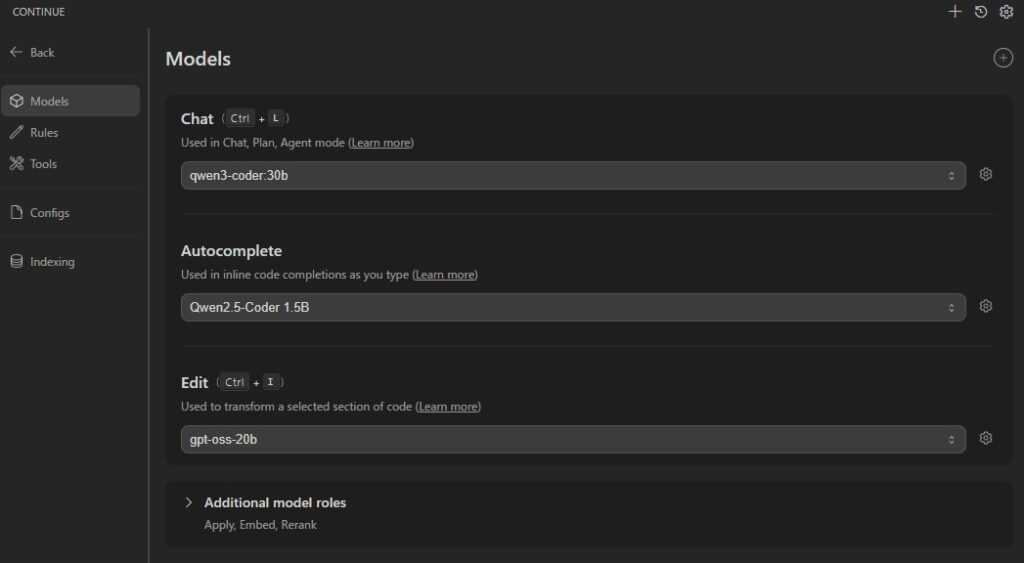
歯車マークを押すと設定が可能です。Modelsタブを押すと、チャット・オートコンプリート・コーディングでどのモデルを使うか指定できます。
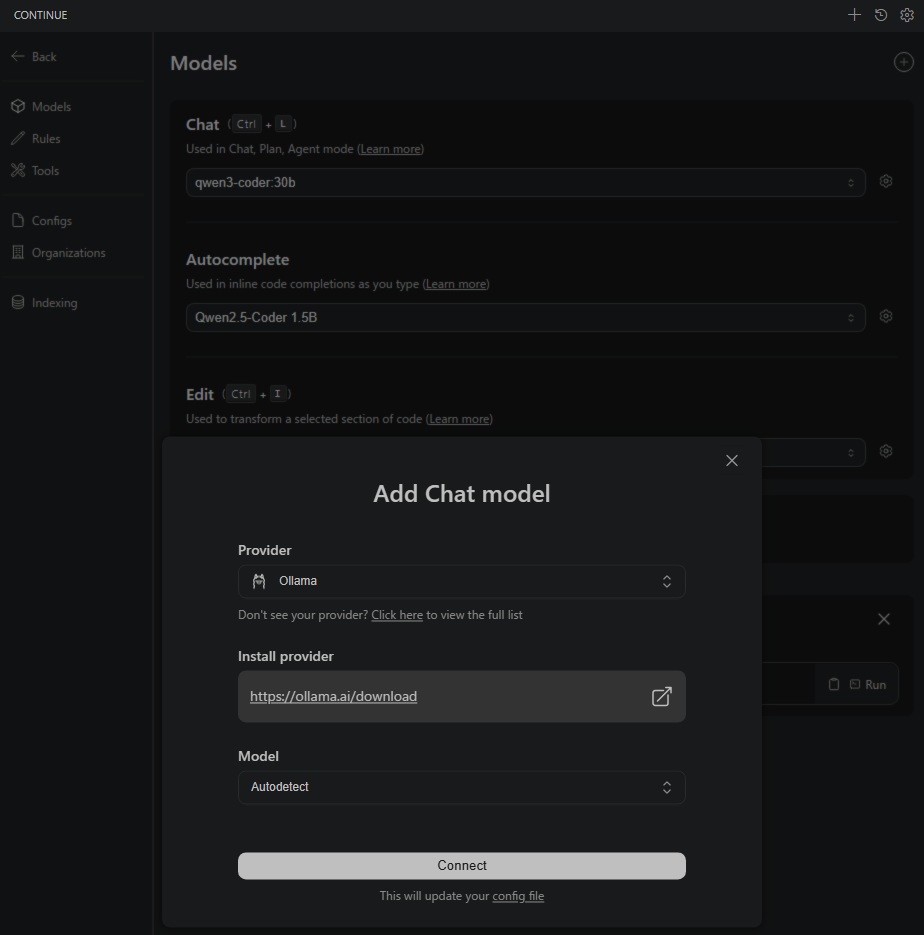
左上の丸印に+のボタンをおすとチャットモデルの追加ができます。
ProviderはOllama、ModelはAutodetectを選んでおくと、インストール済みのモデルを探してくれます。
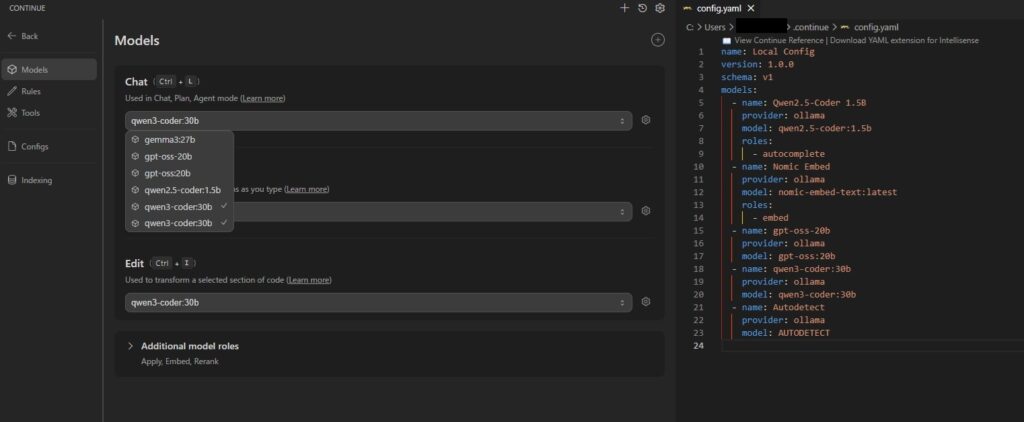
ドロップダウンリストにOllamaにインストール済みのモデルが出てくると思います。
ちなみにドロップダウンリストの横の歯車マークを押すとyamlファイルが表示されます。自分で各機能でどのモデルを表示させるか定義することが出来ます。
私はautocompleteでqwen2.5-coderだけを出すような設定にしています。
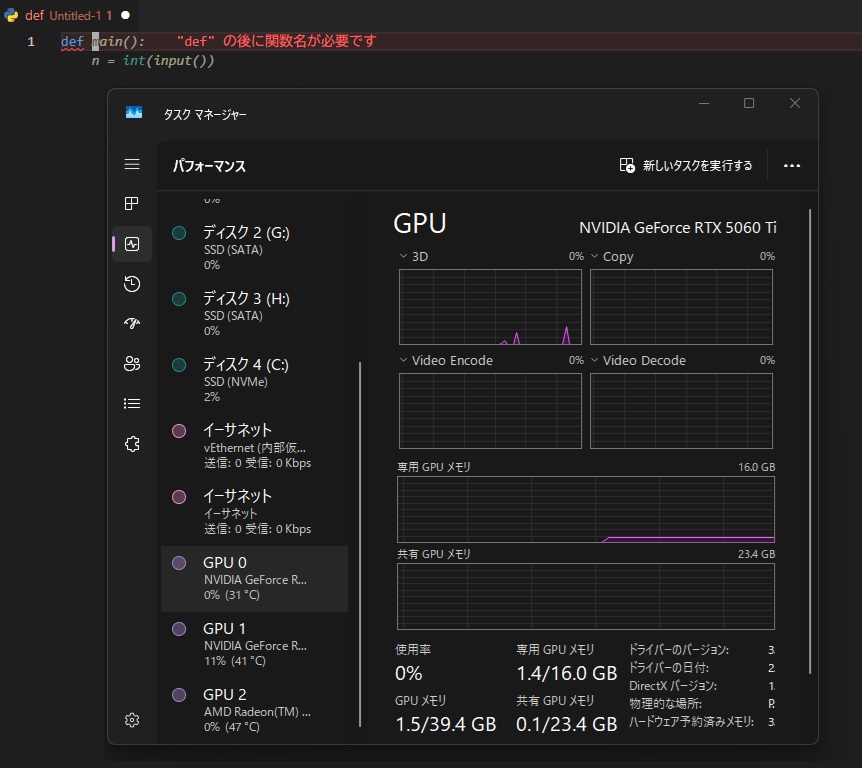
早速オートコンプリート機能を試してみましょう。defと打っただけで候補を提案してくれました。もちろんローカルLLMなのでネットワーク通信は行われません。また、モデルはqwen2.5-coderを使っています。
③-2 VSCodeの設定(Ollamaをホストしていない同一ネットワーク上の端末からContinueを使う場合)
基本的には③-1ですが、少し異なる部分がありますのでそこを補足します。
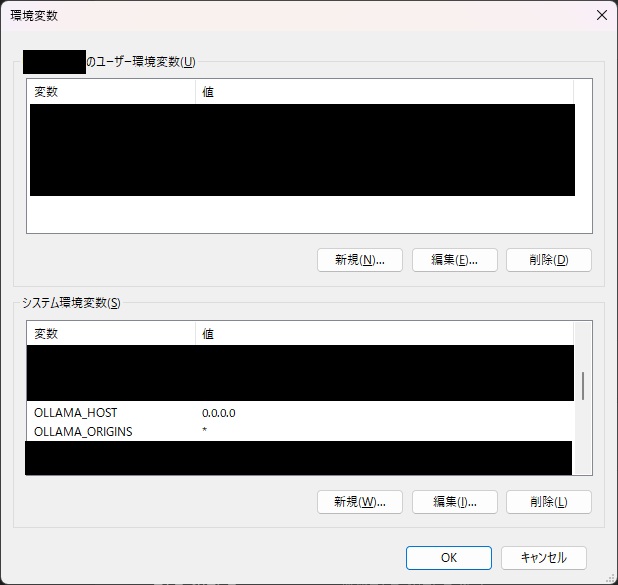
まず、Ollamaをホストしている端末のシステム環境変数に「OLLAMA_HOST」と「OLLAMA_ORIGINS」を追加します。
OLLAMA_HOSTはリクエストを待ち受けるインターフェースとポートを指定します。0.0.0.0で全てのLAN上のIPからの通信を受け付けます。
OLLAMA_ORIGINSはCORSを許可するオリジンをカンマ区切りで指定します。*をつけておくとすべて許可します。
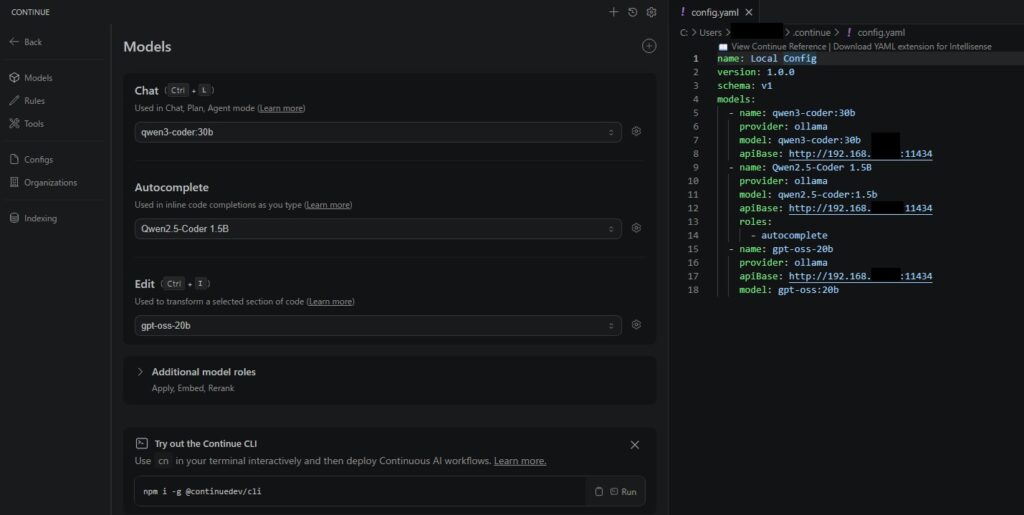
Continueを使いたい端末(非Ollamaホスト端末)にContinueをインストールし、モデルの設定を開きます。
丸印に+のアイコンからOllamaをプロバイダーに選んでいいのですが、Ollamaが入っていないのでモデルは当然見つかりません。
ドロップダウンリスト横の歯車マークを押し、config.yamlに画像のようにapiBaseにOllamaをインストールした端末のipアドレスとOllamaのリクエストを受け付けているポート番号(デフォは11434)を指定し、モデル名を正確に記載します。
ここでいうモデル名はOllama上で表示されているモデル名です。huggingface等のモデル名と違う名前で自分でモデルをインポートしている場合は、その名前を記載しないと呼び出せませんので注意。
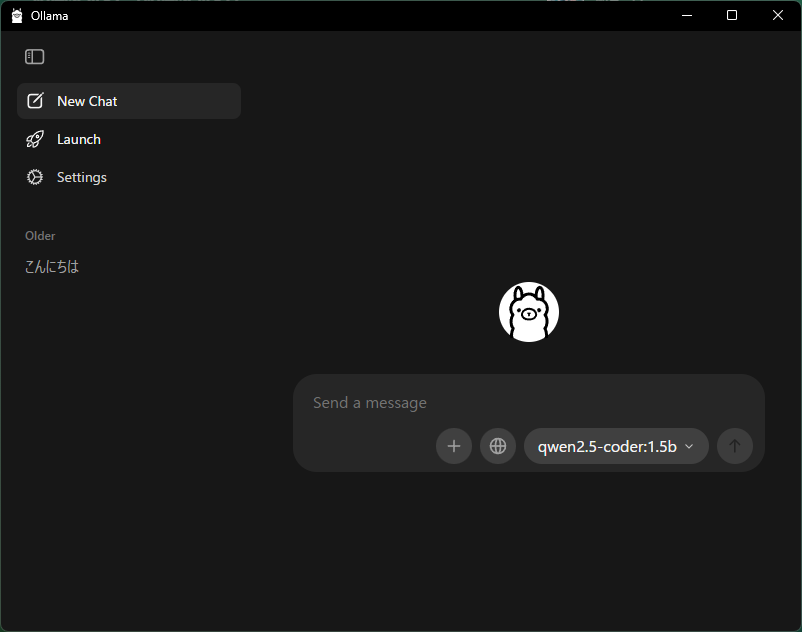
簡単な確認方法は下の図のように、Ollamaを立ち上げた際のチャット画面にあるリストを確認するのがいいでしょう。
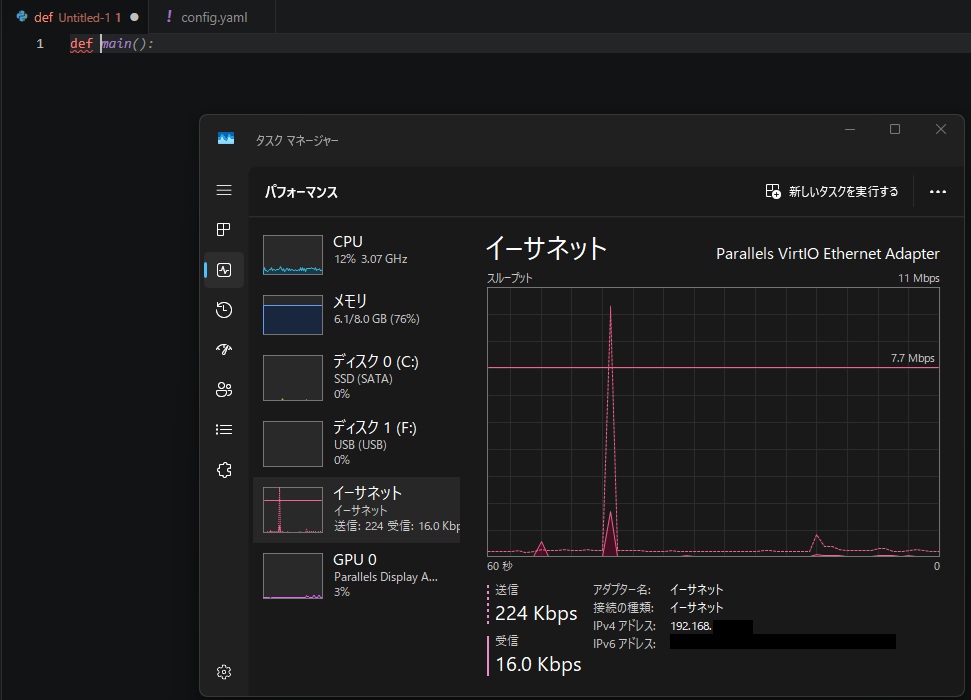
では、さっそくオートコンプリート機能を使ってみます。今回Continueをインストールした端末はMacStudioの仮想マシンにインストールしたWindowsにリモートデスクトップ接続でテストします。メモリは8GBしか割り当てていないため、LLMを呼び起こすには厳しいスペックです。
しかし、Ollamaをホストしている端末は別PCのため、ばっちりオートコンプリートの恩恵を受けられます。
ネットワークへの負荷もほぼなく、せいぜい入力した際に数百KB程度の通信が発生する程度だと思います。
コメント